
(Not so) Stupid Question 292: How does blue-green deployment work?
It’s late at night and I’m battling an imaginary cold as I’m typing this, thankful I cancelled my ACL knee surgery planned for tomorrow. Logistically it simply can’t be done. What is more important, each day offers thrilling happenings that put me to bed with exciting cliffhangers waiting to be pulled down from the repo the next day. Exciting times, busy times.

We are getting closer to our first ‘official’ release in November. One of the things we have focused on is our deployment pipeline. As we switched from Azure Cloud Services to VM’s on Azure we unfortunately went from blue-green deployment to what I call replacement deployment. This is one of the stories on our board that we haven’t done yet- but we have agreed that other stories can take precedence (such as performance). Let me first explain what blue green deployment is by discussing replacement deployment. The term ‘replacement deployment’ is something I’ve made up, it surely has a better name so let me know in the comment section. Anyway.
It’s a deployment method that is quite common. A new release simply replaces the old one- which means that regardless the speed and ease of the process some downtime can be expected- and the amount of downtime varies and depend on a number of factors I’ll skip for now.
We commit to Github, our build server pulls down the branches, builds and runs tests and metrics, creates packages for Octopus and pushes them to the ‘edge’ node. From there one we move the packages and deploy to our dev environment, then QA environment, and from there to local installs for clients, as well as our SaaS service hosted on the Azure VM’s. As it does so we do have some downtime, so we only do it at certain times. We are soon setting up our blue green deployment, now that we have set up a proxy service that abstracts away the location of the nodes (VM’s). We are using Azure slotsfor this, and this is how blue-green deployment works:
In contrast to the traditional deployment model blue-green deployment has no downtime and is quickly becoming the new norm. Hopefully.
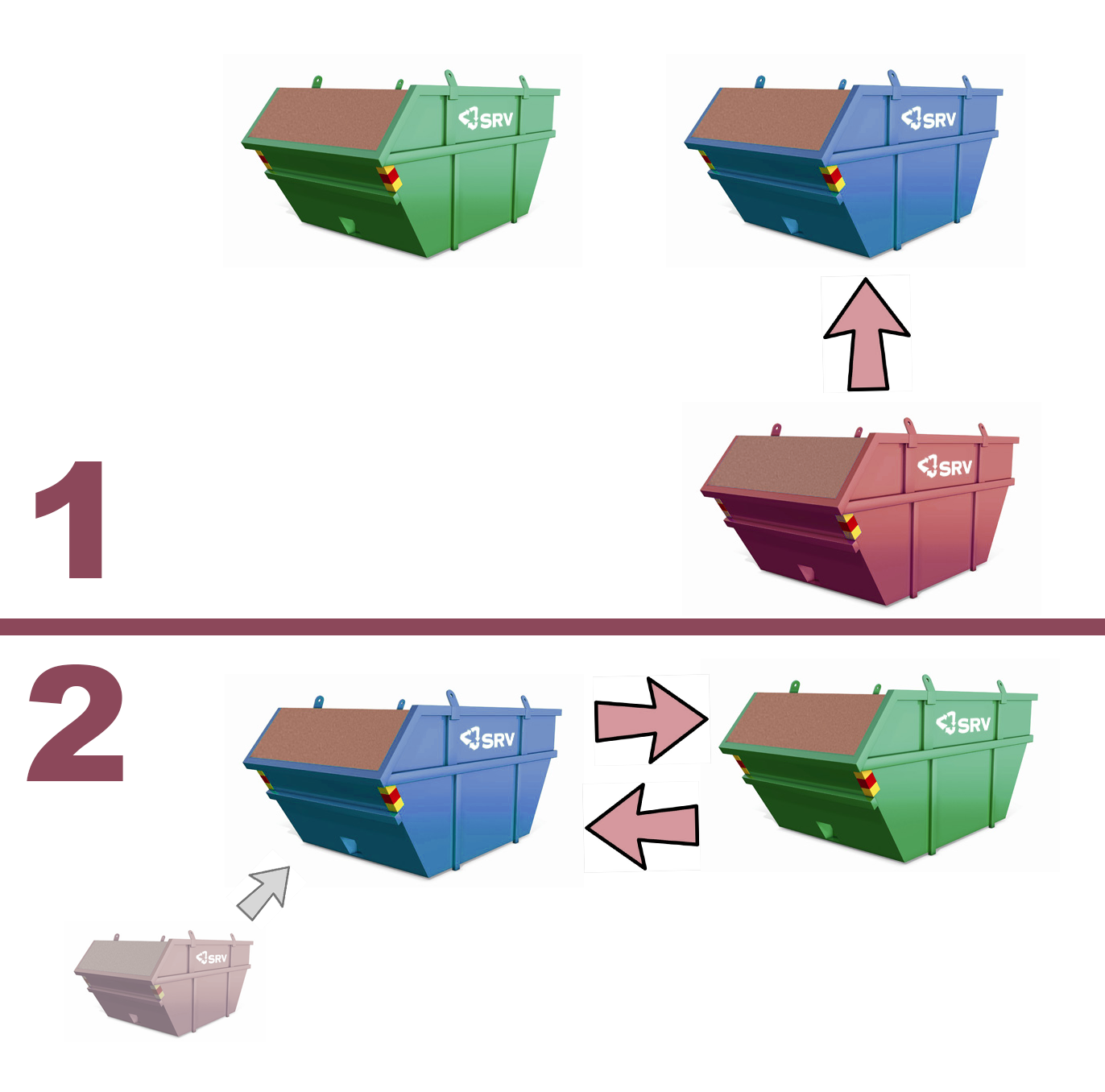
With blue-green deployment you have two working version of your production system. Identical in every way expect location, and traffic, and release version. The ‘green’ deployment is the one that receives the traffic, the blue one does not expose its endpoints and therefore has no traffic. As you have a new release coming out you simply deploy to the blue environment, and verify the deploy went well and maybe also making sure there are no surprises. Once you are confident all is good, the traffic is directed to the blue deployment that now has become ‘green’ (as it is now active) and the previously active and green deployment is considered ‘blue’.
This has of course several benefits. Besides no downtime (and thus no pressure or rushed deployment) it also allows one to sync multiple deployments. In an ideal world the microservices we have, as well as the monolithic client, would not rely on each other. Unfortunately, that is not the case for us. We haven’t even reached our v1 and the system is constantly undergoing a lot if changes as we are trying to define the domain context and boundaries for the parts involved. As a result we often have to adjust parts of the client as we add new features in the services and thus we need to sync the deployment of the two or more parts. A traditional deployment would mean that we would have significant downtime and risk that the wrong client talks to the wrong version of the service. With blue green deployment we simply switch with our proxy. The third benefit is being able to quickly do rollbacks. Even though we do post deployment integration tests (besides the pre deployment system integration tests) we might still have a critical error and we should always be prepared for a quick rollback.
How do you deploy? And what would an ideal deployment pipeline look like?
Comments
It totally depends on your architecture. I have a mixed scenario with a website, api and back-end services. The back-end services deploy quite nicely because they are scaled out. I use the rolling deployment option in Octopus so I can determine how many nodes are down at any one time. As for the api and website, I haven't addressed that yet but there are options available.
Great article, thanks for posting. I have been in a couple different environments where we've used blue green deployments. Very similar concepts as you mention above. The one piece that seemed to be different is how we've decided to validate the blue environment. In one case, we merely fired a couple http requests to critical endpoints in the application to make sure everything was up in running. In others, we did some manual integration testing. The best approach in my opinion though is using automated ui tests (ie selenium, smart bear). I'm curious which approach you've taken...
Last modified on 2016-10-11