
Optical Character Recognition with Ocradjs
Scroll down to see the code if that’s all you are interested in :)
The code is on GitHub, but it’s not really a lot of code. To run the app install node and npm install express –g and use the npm start command in the same folder as app.js (type these commands in the node command prompt or other command line tool).
A little bit on Optical Character Recognition
Mimicking human behavior and characteristics in computer science has always been one of the biggest challenges. Let’s take speech recognition as an example. As humans we learn to take into account tone, context, the persons way of talking, separate idiomatic expressions from ordinary expressions, understand different accents and dialects and more. And still we often get it wrong. To put together calculations that take into account all those things is a big challenge as each word can change at the modest modification of so many factors that build up a sentence. In character recognition we have the same challenge. If you think about last time you struggled to read somebody’s handwriting, maybe your own, and how your mind had to work extra hard puzzling together the context, recognizing patters, try different variations of characters and words, alignment and size of the written text and more. And what if that was written on top of an image giving the text a busy background? With the incredible mind at work we might be able to decipher the text, but we’ve practiced since young age not only writing in different ways, but reading different fonts as well as extracting and interpreting the patterns found after finding the right context. Optical Character Recognition is manual or technical conversion of an image to text, and although we have come quite fare we still haven’t been able to fully mimic the human mind.
OCR has been around for quite long, and we have all encountered it. Sitting here on this United Airline airplane on my way to US I’ve just been handed yet another form to fill out by hand for immigration

There are white boxes where you have to write, forcing a somewhat normalized handwriting that make calculations easier (also people tend to write more sloppy on officially looking forms). I can’t use a red pen, or a pencil as color processing later to remove noise might remove parts of the text I’ve written.
The form will be scanned, then the digitalized form will maybe go through something along the line of these processes:
First the layout of the form will be matched to an existing defined form layout after detecting the layout presumably using some preprocessing to enhance lines and detect crossings
Afterwards the next step might be eliminating background noise. Since this form is blue I assume that a color filter will be used, and most likely that the logo and the numbers on the left will be retained for guidance and information.
Before starting on the data extracting the remaining image needs to be enhanced. Smoothing and normalization is applied, skew and slant detection (see why those little squares are so important?).
Afterwards data extraction can begin by recognizing characters based on stroke thickness, proximity of strokes to each other, detecting edges, color threshold value and so on. Different models exist and the math behind them is honestly a bit over my head although I’ve tried to learn.
Obligatory disclaimer
I think you get the idea how it works, and the challenges that come with it- however the steps vary and the different methods applied and the algorithms are complex.
With the above in mind let’s explore another OCR library (last time it was the Windows Runtime OCR library), this time Ocrad.js, a port of the Ocrad project. It is quite fast, does not rely on an executable and a tedious setup, and is open source. I’ve kept the example simple, but to avoid cross-origin issues I’ve simply used node to spin up a webserver to host the application and the images used as an example to keep everything within in the same domain.
Setting up a node project with express (not needed for Ocrad but used for this demo)
To recreate the basic structure of the project you need to run the following commands (assuming you have node downloaded and installed):
*cd C:\Users\YourUserName*
md SomeDir
cd SomeDir
npm install express –g
npm install -g express-generator
express OcradJs
cd OcradJs
npm install
npm start
What that the above does
In short that creates a solution folder called SomeDir, installs express globally, the installs the express scaffoolder which creates the basic project structure- we use it by typing in express then the name of what we want our project to be called, navigates to that folder and runs the package.json file that express generated so dependencies (such as bodyparser which isn’t included in express anymore) can be pulled down. Npm start spins up the whole thing by looking for an app.js file.
You can navigate to the application in you browser using http://localhost:3000/
Ocrad.js can be downloaded from Github, and you only really need the ocrad.js file
If you want to try out the image ‘reading’ capabilities before you use it in a projectOcrad.js has a site that lets you try out with different image or scribbles.
Add the Ocrad.js script file to the javascripts folder, and an image with text to the images folder.
Open up index.jade under the views folder, this is basically our index page. Since I haven’t done jade in a while and always mess up something when I try I’ve cheated a bit and after doctype html added: “html.” so I can write ordinary markup afterwards as long as I respect the initial indentation. You can either do the same, use a different view engine or simply write jade-style.
The layout for the app
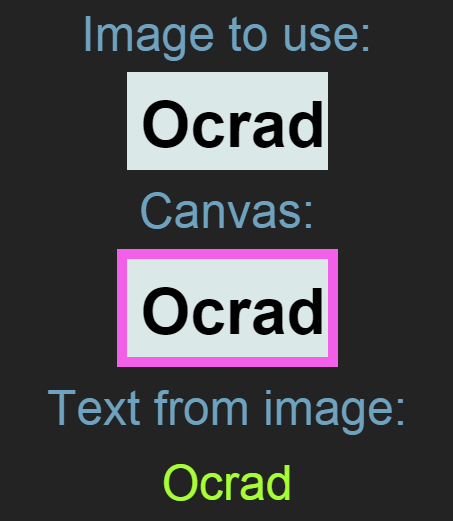
My layout is simply and image, a canvas, and somewhere to output the text. I’ve added some descriptive divs and some CSS3 animations for fun, but those are not needed at all. I’ve also written JavaScript in the markup which I rarely do- simply to allow you to see all the elements working together without having to switch between files. With that said, let’s talk about using Ocrad.
In this example to provide something visual I’ve added an image to our page, and then a canvas which is set to hold that image after the image has finished loading. I then use the canvas context, pass it in to the Ocrad library which returns the text.
Ocrad.js
The library has only one function which is global, OCRAD. You can pass in either:
A canvas element
A Context2D instance
or ImageData
- and it returns the converted text.
The code explained
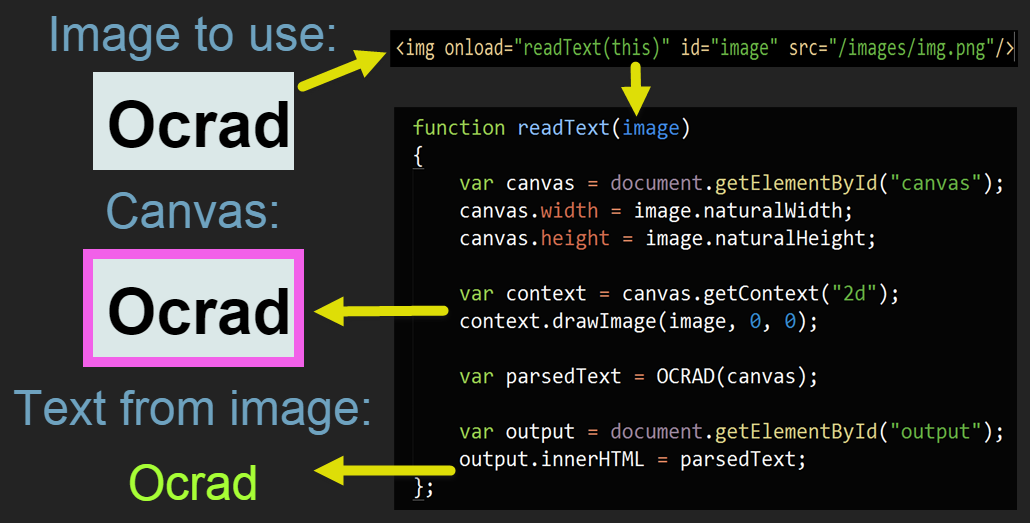
Let’s walk through the code. First of all, I’m reading in the script (and stylesheet), then a function that will be called when the image has loaded passing in the image as an argument. I then set the canvas height and width to that of the image- this is purely esthetical and is not needed for the OCR.
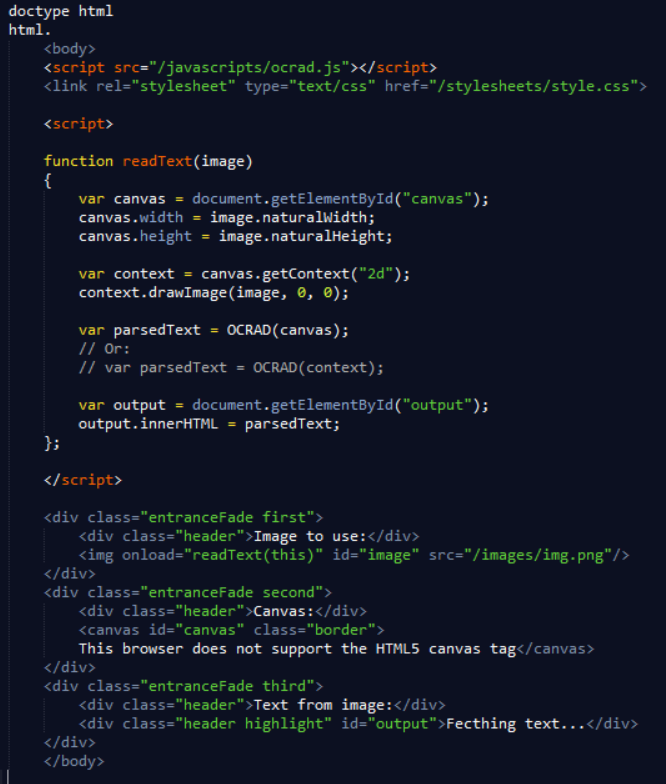
[sourcecode language=“html”]
doctype html
html.
<script>
function readText(image)
{
var canvas = document.getElementById("canvas");
canvas.width = image.naturalWidth;
canvas.height = image.naturalHeight;
var context = canvas.getContext("2d");
context.drawImage(image, 0, 0);
var parsedText = OCRAD(canvas);
// Or:
// var parsedText = OCRAD(context);
var output = document.getElementById("output");
output.innerHTML = parsedText;
};
</script>
<div class="entranceFade first">
<div class="header">Image to use:</div>
<img onload="readText(this)" id="image" src="/images/img.png"/>
</div>
<div class="entranceFade second">
<div class="header">Canvas:</div>
<canvas id="canvas" class="border">
This browser does not support the HTML5 canvas tag</canvas>
</div>
<div class="entranceFade third">
<div class="header">Text from image:</div>
<div class="header highlight" id="output">Fecthing text...</div>
</div>
</body>
[/sourcecode]
Next we get the canvas context and draw the image we passed in on to the canvas. At that point we can call the OCRAD(arg) function and either pass in the canvas, or the context. The parsing might take some time, for this simple image is fairly fast and the CSS3 animations mask the lag- but keep it in mind. Lastly I output the recognized text and that’s it.
[sourcecode language=“javascript”]
function readText(image)
{
var canvas = document.getElementById(“canvas”);
canvas.width = image.naturalWidth;
canvas.height = image.naturalHeight;
var context = canvas.getContext("2d");
context.drawImage(image, 0, 0);
var parsedText = OCRAD(canvas);
// Or:
// var parsedText = OCRAD(context);
var output = document.getElementById("output");
output.innerHTML = parsedText;
};
[/sourcecode]
Let me know if you end up doing using the library in a project, for what and how? And don’t forget to let me know if you know of similar libraries/engines you would recommend I try out.
best of luck!
Comments
Last modified on 2014-11-07